数据库易忘知识点总结
数据库的基本知识点
1 数据库的基本常用知识点
1.1 在创建数据库时,指定数据库编码命令
create database ads character set 'utf8'
如图所示 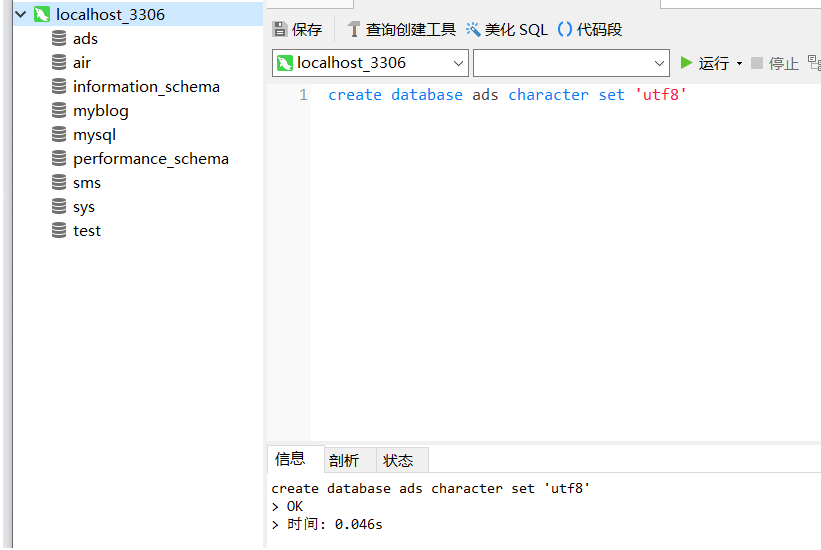
1.2 对数据表的操作
删除数据
语法:
delete from 表名 [where 条件]
注意:
* 如果不加条件,则删除表中所有记录。
* 如果要删除所有记录
delete from 表名—不推荐使用。有多少条记录就会执行多少次删除操作。
* TRUNCATE TABLE 表名;–推荐使用,效率更高,先删除表,然后创建相同的表。update 表名 set 列名1 = 值1,列名2 = 值2,…[where 条件]; 注意:如果不加条件,则会修改所有的记录;
多表查询取出重复的行
关键字 distinct
DQL:查询语句
- 排序查询
语法:order by 子句
排序方式: ASC:升序;DESC:降序
注意:如果有多个排序条件,则当前的条件值一样时,才会判断第二个条件。 聚合函数:
(1)count:计算个数
(2)max
(3)min
(4)sum
(5)avg注意:聚合函数的计算排除null值:选择不包含非空的列进行计算;IF NULL
分组查询
语法:group by 分组字段
- 排序查询
1.4 数据库三范式
- 第一范式 (1NF)
属性不可再分
- 第二范式(2NF)
每个非主属性完全函数依赖于键码 - 第三范式(3NF)
非主属性不传递函数依赖于键码
1.5 内连接、交叉连接、外连接
- 概念:根据两个或多个表的列之间的关系,从这些表中查询数据。分为三种:内连接、外连接、交叉连接。
- 目的:实现多个表查询操作
1.6 MYSQL两种存储引擎的区别(事务,锁级别等等),各自的使用场景
区别
- 事务 :InnoDB是事务型的,可以使用commit,rollback语句。
- 并发 :MyISAM只支持表级锁,InnoDB还支持行级锁。
- 外键 :InnoDB支持外键。
- 备份 :InnoDB支持在线热备份。
- 崩溃恢复 :MyISAM崩溃后发生损坏的概念要比InnoDB高很多,而且恢复速度更慢。
- 其他特性 :MyISAM只支持压缩表和空间数据索引。
应用场景
- MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。
- InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。
1.7 drop、delete、truncate的区别
说明: drop、delete、truncate都表示删除
- delete用来删除表的全部数据(一般不推荐使用)或者部分数据行,执行delete之后,用户需要提交(commit)或者回滚(rollback)来执行删除或者撤销删除;delete命令会触发这个表上的所有的delete触发器;
- truncate常用来删除表中的所有数据行,他的工作原理是先删除表再新建相同的表,对比delete执行删除表全部数据时,delete是一行一行的执行SQL语句,因此比delete更快。这个操作不能回滚,也不会触发这个表上的触发器;
- drop从数据库删除表,连带着这个数据表的所有数据行、索引和权限也会被删除,所有的DML触发器也不会被触发,这个命令也不能被回滚。
1.8 创建索引
- 语法
- alter table
table_nameadd primary key(column) —创建主键 - alter table
table_nameadd unique index(column) —创建唯一索引 - alter table
table_nameadd index index_name(column,column,…) —创建普通索引 - alter table
table_nameadd FULLTEXT (column) —创建全文索引
- alter table
1.9 查看表的所有所以
- show index from table_name;
1.20 查看执行SQL语句时是否走索引
- explain select * from table_name —- 关键字explain 后面跟执行的SQL语句
2 事务
2.1 事务的基本介绍
概念:如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。
操作:
* 开启事务 start transaction;
* 回滚 rollback;
* 提交 commit 2.2 事务的四大特性
* 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。
* 持久性:当事务提交或回滚后
* 隔离性:多个事务之间,相互独立。
* 一致性:事务操作前后,数据总量不变。 2.3 事务的隔离级别
概念:多个事务之间隔离的,相互独立的,但是如果多个事务操作同一批数据,
则会引发一些问题。
* 脏读:一个事务,读取到另一个事务中没有提交的数据。
* 不可重复读(虚读):在同一个事务中,两次读取到的数据不一样。
* 幻读:一个事务操作数据表中的所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改
隔离级别:
1. read uncommitted:读未提交
产生的问题:脏读、不可重复读、幻读
2. read committed:读已提交(oracle)
产生的问题:不可重复读、幻读
3. repeatable read :可重复读(mysql默认)
产生的问题:幻读
4. serializable:序列化(串行化)
可以解决所有的问题
注意:隔离级别从小到大安全性越来越高,但是效率越来越低 2.4 数据库查询隔离级别
select @@tx_isolation 如图所示 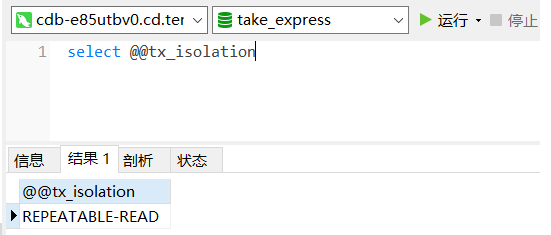
2.5 数据库设置隔离级别
set global transaction isolation level 级别字符串; 3 事务隔离性的实现————常见的并发控制技术
并打控制技术是实现事务隔离性以及不同隔离级别的关键
4 索引的分类
mysql常见的索引类别有:主键索引、唯一索引、普通索引、全文索引、组合索引
- primary key 主键索引 alert table
table_nameadd primary key(column) - unique 唯一索引 alert table(
table_name) add unique(column) - index 普通索引 alert table
table_nameadd index index_name(column) - fulltext全文索引 alert table
table_nameadd fulltext(column) 组合索引 ALTER TABLE
table_nameADD INDEX index_name (column1,column2,column3)5 那些情况下索引会失效
如果条件中有or,即使其中有条件带有索引也不会使用(这也是为什么尽量少用or的原因,要使用or,有想要索引生效,只有将or条件中的每个列都加上索引)
对于多索引列,不是使用的第一部分,则不会使用索引
like查询是以%开头
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
如果mysql估计使用全表扫描要比使用索引快,则不使用索引
6 索引有B+索引和hash索引
* BTree索引是最常用的mysql索引算法,因为他可以用在=、>、>=、<、<=和between这些比较操作符上,
而且还可以用于like操作符,只要他的查询条件不是一个以通配符开头的常量;如果以通配符开头,或者
没有使用常量,则不会索引;
* hash索引只能用于对等比较例如=、<=>(相当于=)操作符。由于hash索引是一次性定位数据,不像
Btree索引需要从根节点定位到枝节点,最后才能访问到页面节点,这样多次IO访问,所以hash检索效率
远比Btree索引高
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
1. Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。
2. 联合索引中,Hash索引不能利用部分索引键查询。
对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引
的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
3. Hash索引无法避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算
前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
4. Hash索引任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一
个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也
无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
5. Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash
值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。7 聚集索引和非聚集索引的区别
7.1 两者的根本区别是标记的排序与索引的排序顺序是否一致。
1. 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
2. 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上连续存在
3. 聚集索引查询数据速度快,插入数据速度慢;非聚集索引反之。 8 数据库的优化
思路:从sql语句优化和索引两个方面考虑
实践中,mysql的优化主要涉及SQL语句及索引的优化、数据表结构的优化、系统配置的优化和硬件的优化四个方面
如图所示
8.1 SQL语句的优化
1. 优化insert语句:一次插入多个值;
2. 尽量避免在where子句中使用 != 或<>操作符,否则将导致引擎放弃使用索引而进行全表扫描;
3. 优化嵌套查询:子查询可以被更有效率的连接(join)替代
测试效果图如下,两种方式的SQL语句,测试执行时间,比较效率
(1) 使用连接(join)查询多表,查询时间效率如下图所示 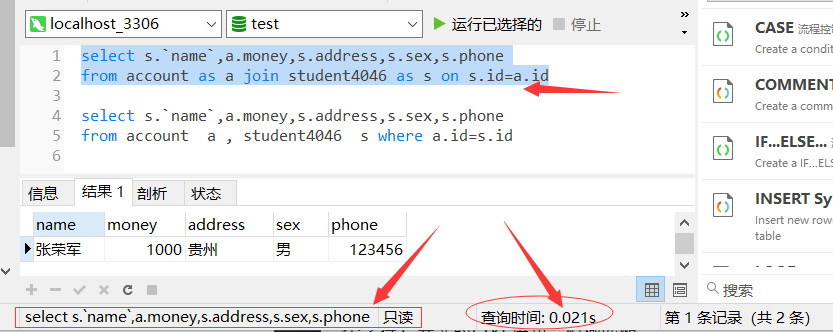
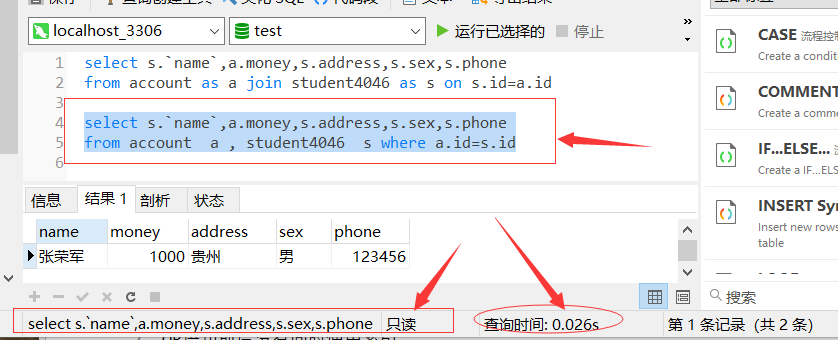
8.2 索引的优化
建议在经常作查询选择的字段、经常作表连接的字段以及经常出现在order by、group by、distinct 后面的字段中建立索引。但必须注意以下几种可能会引起索引失效的情形:
1. 以“%(表示任意0个或多个字符)”开头的LIKE语句,模糊匹配;
2. OR语句前后没有同时使用索引;
3. 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型);
4. 对于多列索引,必须满足最左匹配原则(eg,多列索引col1、col2和col3,则 索引生效的情形包括col1或col1,col2或col1,col2,col3)。8.3 数据表结构的优化
数据库表结构的优化包括选择合适数据类型、表的范式的优化、表的垂直拆分和表的水平拆分等手段。- 上一篇: 数据库易忘知识点总结
- 下一篇: Redis之java客户端
